Intelligenza artificiale: cos’è, tutti gli argomenti
Argomenti sull’Intelligenza artificiale
Intelligenza artificiale
L’intelligenza artificiale, nel suo significato più ampio, è la capacità o il tentativo di un sistema artificiale di simulare l’intelligenza umana attraverso l’ottimizzazione di funzioni matematiche.
Intelligenza artificiale forte
L’intelligenza artificiale forte o intelligenza artificiale generale è la capacità di un agente intelligente di apprendere e capire un qualsiasi compito intellettuale che può imparare un essere umano. È l’obiettivo principale di alcune delle ricerche nell’intelligenza artificiale e un argomento comune nella fantascienza e nella futurologia. Alcune fonti accademiche riservano il termine “IA forte” a quei programmi informatici in grado di essere senziente e di avere una coscienza. Il concetto di IA forte è stato analizzato e contestato dal filosofo John Searle nel suo esperimento della stanza cinese. Egli ha affermato:…
Intelligenza artificiale generativa

L’intelligenza artificiale generativa è un tipo di intelligenza artificiale che è in grado di generare testo, immagini, video, musica o altri media in risposta a delle richieste dette prompt. I sistemi di intelligenza artificiale generativa utilizzano modelli generativi, che sono modelli statistici di una distribuzione congiunta di una variabile osservabile e di una variabile dipendente, che nel contesto del data mining è detta variabile target. Un esempio di questi modelli sono i modelli linguistici di grandi dimensioni che producono dati a partire da un dataset di addestramento utilizzato per crearli.
20q

20q è un’implementazione avanzata di un classico problema di intelligenza artificiale, messo sotto forma di un semplice videogioco. Il giocatore pensa in precedenza a un qualunque oggetto e il programma tenta di indovinarlo ponendogli domande che possono avere una risposta del tipo “Sì” o “No”.
Acceleratore di Intelligenza Artificiale
Un acceleratore di Intelligenza Artificiale è una classe di microprocessori progettati per fornire accelerazione hardware a reti neurali artificiali, visione artificiale e algoritmi di apprendimento automatico per la robotica, l’Internet delle cose e altre applicazioni basate sull’uso dei dati.
Affective computing
L’Affective computing è un ramo specifico dell’intelligenza artificiale che si propone di realizzare calcolatori in grado di riconoscere ed esprimere emozioni.
Agente intelligente

L’agente è una qualunque entità in grado di percepire l’ambiente che lo circonda attraverso dei sensori e di eseguire delle azioni attraverso degli attuatori. Ad esempio, in un essere umano alcuni sensori sono gli occhi e le orecchie, mentre gli attuatori possono essere le mani, i piedi o più in generale i muscoli.
Albero di decisione

Nella teoria delle decisioni, un albero di decisione è un grafo di decisioni e delle loro possibili conseguenze, utilizzato per creare un ‘piano di azioni’ (plan) mirato ad uno scopo (goal). Un albero di decisione è costruito al fine di supportare l’azione decisionale.
Algoritmo anytime
Un algoritmo anytime è un algoritmo che è in grado di restituire una soluzione valida anche se viene interrotto anticipatamente. Mentre molti algoritmi forniscono una soluzione dopo una certa quantità di calcoli, e non sono in grado di restituire nessun risultato utile fino al completamento dei medesimi, un algoritmo anytime è in grado di fornire una soluzione parziale se interrotto anticipiatamente, e aumentando il tempo a disposizione aumenta anche la qualità attesa della soluzione. Un esempio è l’algoritmo di Newton-Raphson per il calcolo dello zero di una funzione.
Algoritmo di Canny

Nell’elaborazione di immagini, l’algoritmo di Canny è un operatore per il riconoscimento dei contorni ideato nel 1986 da John F. Canny. Utilizza un metodo di calcolo multi-stadio per individuare contorni di molti dei tipi normalmente presenti nelle immagini reali. Canny ha anche prodotto una teoria del riconoscimento dei contorni che si propone di spiegare i fondamenti di questa tecnica.
Algoritmo evolutivo
Un algoritmo evolutivo è un algoritmo euristico che si ispira al principio di evoluzione degli esseri viventi. Semplificando si può affermare che un algoritmo evolutivo prevede di partire da una soluzione e di farla evolvere con una serie di modifiche casuali fino a giungere ad una soluzione migliore. Concettualmente, un algoritmo evolutivo è molto simile ad un algoritmo genetico ed infatti si differenzia da quest’ultima categoria principalmente per l’assenza del meccanismo di crossover con cui più soluzioni appartenenti ad una popolazione in fase di evoluzione, vengono ricombinate.
Algoritmo genetico
Un algoritmo genetico è un algoritmo euristico utilizzato per tentare di risolvere problemi di ottimizzazione per i quali non si conoscono altri algoritmi efficienti di complessità lineare o polinomiale. L’aggettivo “genetico”, ispirato al principio della selezione naturale ed evoluzione biologica teorizzato nel 1859 da Charles Darwin, deriva dal fatto che, al pari del modello evolutivo darwiniano che trova spiegazioni nella branca della biologia detta genetica, gli algoritmi genetici attuano dei meccanismi concettualmente simili a quelli dei processi biochimici scoperti da questa scienza.
Allen Institute per l’IA
L’Allen Institute per l’IA è un istituto di ricerca senza scopo di lucro fondato nel 2014 dal filantropo Paul Allen, già cofondatore di Microsoft. L’istituto conduce attività di ricerca e sviluppo ad alto impatto sull’intelligenza artificiale al servizio del bene comune. Oren Etzioni è stata nominata da Paul Allen a settembre 2013 per dirigere la ricerca presso l’istituto. Dopo aver guidato l’organizzazione per nove anni, Oren Etzioni si è dimesso dal ruolo di CEO il 30 settembre 2022. È stato sostituito ad interim dal coordinatore del progetto Aristo dell’istituto, Peter Clark. Il 20 giugno 2023, AI2 ha annunciato Ali Farhadi come prossimo CEO a partire dal 31 luglio 2023. Il consiglio di amministrazione della società ha formato un comitato di ricerca per un nuovo amministratore delegato. AI2 ha anche un ufficio attivo a Tel Aviv, Israele.
AlphaFold
AlphaFold è un programma di intelligenza artificiale sviluppato da DeepMind (Alphabet/Google) per predire la struttura tridimensionale delle proteine. Il programma è stato progettato come un sistema di deep learning.
Apprendimento automatico

L’apprendimento automatico è una branca dell’intelligenza artificiale che raccoglie metodi sviluppati negli ultimi decenni del XX secolo in varie comunità scientifiche, sotto diversi nomi quali: statistica computazionale, riconoscimento di pattern, reti neurali artificiali, filtraggio adattivo, teoria dei sistemi dinamici, elaborazione delle immagini, data mining,…
Aritmetica tipografica
In matematica, l’aritmetica tipografica, o AT è un sistema formale assiomatico che descrive i numeri naturali che compare nel libro di Douglas Hofstadter Gödel, Escher, Bach. È una implementazione dell’aritmetica di Peano.
Association for the Advancement of Artificial Intelligence
L’Association for the Advancement of Artificial Intelligence (AAAI) è un’associazione scientifica internazionale dedita a promuovere la ricerca nell’ambito dell’intelligenza artificiale, a migliorare la conoscenza pubblica dell’intelligenza artificiale, la formazione didattica dei professionisti, a fornire informazione e assistenza ai decisori e ai finanziatori della ricerca riguardo alle potenziali direttrici di sviluppo futuro della ricerca.
Associazione Italiana per l’Intelligenza Artificiale
L’Associazione Italiana per l’Intelligenza Artificiale (AIxIA) è una associazione scientifica senza fini di lucro, fondata nel 1988 da alcuni professori e ricercatori italiani, con lo scopo di promuovere la diffusione dell’intelligenza artificiale in Italia.
Auto-GPT
Auto-GPT è un agente intelligente capace di scomporre un obiettivo assegnatogli in linguaggio naturale e di dedurne delle sotto-attività più semplici che esegue mediante Internet e altri strumenti all’interno di un’iterazione automatica. Esso adotta le API di GPT-3.5 e di GPT-4, configurandosi come una delle prime applicazioni che impiegano GPT-4 per eseguire attività in autonomia.
Auto-organizzazione
Nella teoria dei sistemi, l’auto-organizzazione è principalmente una forma di sviluppo del sistema attraverso influenze ordinanti e limitative provenienti dagli stessi elementi che costituiscono il sistema oggetto di studio e che permettono di raggiungere un maggior livello di complessità. Questo concetto riveste notevole importanza pratica in ambito multidisciplinare, interessando vasti campi sia delle scienze naturali che delle scienze umane. In cibernetica una applicazione pratica consiste nella Self-Organizing Map. Normalmente, i sistemi auto-organizzanti esibiscono proprietà emergenti.
Autonomic computing
L’Autonomic Computing è un’iniziativa avente lo scopo di fornire ai computer gli strumenti necessari per auto-gestirsi senza l’intervento umano.
BabelNet
![]()
BabelNet è una rete semantica multilingue e un’ontologia lessicalizzata. BabelNet è stata creata integrando automaticamente la più grande enciclopedia multilingue – ovvero Wikipedia – con il più noto lessico della lingua inglese – ovvero WordNet. L’integrazione è stata effettuata per mezzo di una mappatura automatica. Le voci mancanti nelle altre lingue sono state ottenute con l’ausilio di tecniche di traduzione automatica. Il risultato è un “dizionario enciclopedico” che fornisce concetti e voci enciclopediche lessicalizzate in molte lingue, collegati tra loro da grandi quantità di relazioni semantiche. Analogamente a WordNet, BabelNet raggruppa le parole in lingue diverse in insiemi di sinonimi, chiamati Babel synset. Per ciascun Babel synset, BabelNet fornisce definizioni testuali in diverse lingue, ottenute da WordNet e da Wikipedia.
Backtracking
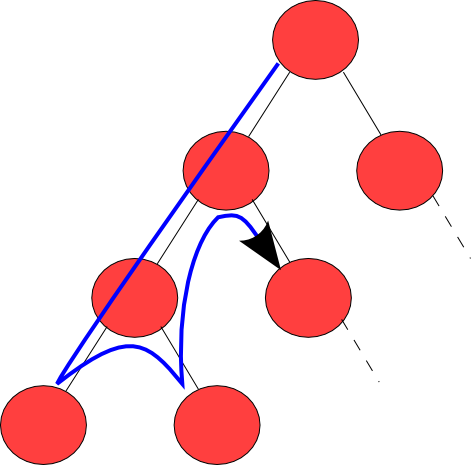
Il backtracking è una tecnica per trovare soluzioni a problemi in cui devono essere soddisfatti dei vincoli. Questa tecnica enumera tutte le possibili soluzioni e scarta quelle che non soddisfano i vincoli.
Bagging
Nell’apprendimento automatico, il bagging è una tecnica dell’apprendimento d’insieme in cui più modelli dello stesso tipo vengono addestrati su insiemi di dati diversi, ciascuno ottenuto da un insieme di dati iniziale tramite campionamento casuale con rimpiazzo (bootstrap). Il nome bagging deriva quindi dall’applicazione della tecnica del bootstrap con l’aggregazione di più modelli (aggregating).
Belief propagation
Nel campo dell’intelligenza artificiale, l’algoritmo belief propagation, noto anche come sum–product message passing, è un algoritmo a passaggio di messaggi (message-passing) per fare inferenza su modelli grafici, quali le reti bayesiane e le reti markoviane.
Bias induttivo
Nell’apprendimento automatico, il bias induttivo di un algoritmo è l’insieme di assunzioni che il classificatore usa per predire l’output dati gli input che esso non ha ancora incontrato.
Blue Brain
Blue Brain è un progetto di ricerca che mira a creare una ricostruzione al computer del funzionamento degli elementi che compongono il cervello del topo. L’obiettivo del progetto non è realizzare un’intelligenza artificiale, ma scoprire le strutture ed i principi fondamentali alla base del funzionamento del cervello del topo, usando una ricostruzione digitale e dettagliata dal punto di vista biologico. Il progetto è stato avviato da IBM, nel maggio 2005, in collaborazione con Henry Markram e con l’École Polytechnique di Losanna in Svizzera.
Boids
Boids è un software di intelligenza artificiale realizzato nel 1986 da Craig Reynolds allo scopo di simulare il comportamento degli stormi di uccelli in volo.
Bot (informatica)
Il bot in terminologia informatica è un programma che accede alla rete attraverso lo stesso tipo di canali utilizzati dagli utenti per svolgere attività di raccolta dati o manipolazione delle piattaforme in rete in maniera autonoma. Programmi di questo tipo sono diffusi in relazione a molti diversi servizi in rete, con scopi vari, ma in genere legati all’automazione di compiti che sarebbero troppo gravosi o complessi per gli utenti.
Campo casuale di Markov

Un campo casuale di Markov, detto anche rete di Markov, è un insieme di variabili casuali che verificano la proprietà di Markov rispetto a un grafo non orientato che rappresenta le dipendenze fra tali variabili. In altre parole, un campo aleatorio si dice markoviano se verifica la proprietà di Markov. L’idea trae origine dalla fisica e in particolare…
CAPTCHA
Con l’acronimo inglese CAPTCHA si denota nell’ambito dell’informatica un test fatto di una o più domande e risposte per determinare se l’utente sia un umano e non un computer o, più precisamente, un bot.
Centro di ricerca tedesco sull’intelligenza artificiale
Il Centro di ricerca tedesco sull’intelligenza artificiale, in tedesco Deutsches Forschungszentrum für Künstliche Intelligenz (DFKI), è un istituto di ricerca pubblico-privato tedesco che si occupa di ricerca nel campo dell’intelligenza artificiale.
Chat bot

Un chatbot, noto anche come chatterbot o robot di conversazione, è un software progettato per simulare una conversazione con un essere umano. L’obiettivo principale di un chat bot è quello di fornire risposte automatiche che possano sembrare umane, utilizzando spesso sistemi di elaborazione del linguaggio naturale (NLP), per analizzare e rispondere alle domande degli utenti. I chat bot vengono utilizzati per una varietà di scopi, tra cui assistenza clienti, guida in linea, e risposte alle FAQ.
Cibernetica

Il termine cibernetica indica un vasto programma di ricerca interdisciplinare, rivolto allo studio matematico unitario degli organismi viventi e, più in generale, di sistemi, sia naturali che artificiali.
La cibernetica: Controllo e comunicazione nell’animale e nella macchina
La cibernetica: controllo e comunicazione nell’animale e nella macchina è un saggio del matematico statunitense Norbert Wiener del 1948, che diede origine all’omonimo filone di pensiero interdisciplinare.
Classificatore bayesiano
Un classificatore bayesiano è un classificatore basato sull’applicazione del teorema di Bayes.
Classificazione multi-etichetta
Nell’apprendimento automatico la classificazione multi-etichetta è una variante del problema della classificazione che ammette per ogni istanza l’assegnazione di più di una etichetta-obiettivo. La classificazione multi-etichetta non deve essere confusa con la classificazione multiclasse, che è invece il problema di categorizzare le istanze in una sola tra più di due classi.
Cleverbot
Cleverbot è un’applicazione web IA che studia come mimare delle conversazioni umane comunicando con gli umani. È stata creata dallo scienziato delle intelligenze artificiali Rollo Carpenter, il quale inventò anche Jabberwacky, un’applicazione simile. Nel primo decennio della sua esistenza, dopo essere stata inventata nel 1988, Cleverbot tenne migliaia di conversazioni con Carpenter e i suoi colleghi. Dal 1997, anno in cui fu lanciato sul web, il numero delle conversazioni ha superato i 65 milioni.
CLIPS
Il software CLIPS è uno strumento per la creazione di sistemi esperti. CLIPS è l’acronimo per C Language Integrated Production System. La sintassi ed il nome del linguaggio sono ispirati dal linguaggio OPS5 e l’algoritmo di riconoscimento di pattern alla base usato è l’algoritmo rete.
Clustering
In statistica, il clustering o analisi dei gruppi è un insieme di tecniche di analisi multivariata dei dati volte alla selezione e raggruppamento di elementi omogenei in un insieme di dati.
Clustering gerarchico
In statistica e apprendimento automatico, il clustering gerarchico è un approccio di clustering che mira a costruire una gerarchia di cluster. Le strategie per il clustering gerarchico sono tipicamente di due tipi:
- Agglomerativo: si tratta di un approccio “bottom up” in cui si parte dall’inserimento di ciascun elemento in un cluster differente e si procede quindi all’accorpamento
Collaborative filtering
Per collaborative filtering si intende una classe di strumenti e meccanismi che consentono il recupero di informazioni predittive relativamente agli interessi di un insieme dato di utenti a partire da una massa ampia e tuttavia indifferenziata di conoscenza. Il collaborative filtering è molto usato nell’ambito dei sistemi di raccomandazione. Una categoria molto nota di algoritmi di tipo collaborativo è la matrix factorization.
Collegamento semantico
Un collegamento semantico è un collegamento che fornisce un’informazione semantica relativa al collegamento stesso (“link”). Un esempio di collegamento semantico è quello che collega due elementi A e B mediante la relazione A è-madre-di B, implicando eventualmente B è-figlio-di A. I collegamenti semantici sono alla base delle reti semantiche.
Computazione evolutiva
La computazione evolutiva è un sottocampo dell’intelligenza artificiale che consiste principalmente nell’ottimizzazione iterativa continua e combinatoria della soluzione di un problema. È nata durante gli anni sessanta guidata dall’idea di automatizzare la risoluzione di problemi.
Computazione evolutiva interattiva
Con il termine computazione evolutiva interattiva ci si riferisce a tutti gli approcci che inglobano una valutazione umana all’interno di un algoritmo di computazione evolutiva. Nella formulazione più semplice possibile, un algoritmo di computazione evolutiva interattiva usa un giudizio soggettivo come propria funzione obiettivo. In una definizione più ampia, esso integra un qualsiasi tipo di interfaccia uomo-macchina all’interno di un algoritmo di computazione evolutiva. In linea generale, si situa l’inizio di tale campo di ricerca agli studi di Richard Dawkins sui cosiddetti biomorfi nel 1986.
Computazione naturale
La computazione naturale nel senso più comune del termine è un sotto-campo dell’informatica e più in particolare dell’intelligenza artificiale, che si occupa dello sviluppo di tecnologie e modelli computazionali ispirati alle metodiche che la natura ha raffinato nel corso dei millenni e sulle quali l’uomo non ha ancora trovato soluzioni adeguate.
Computer organico
Il computer organico è un ipotetico computer basato, invece che su componenti artificiali, su una integrazione fra elementi in silicio e organici.
Conferenza di Asilomar sulla IA Benefica

La Conferenza di Asilomar sulla AI Benefica è stata una conferenza organizzata da Future of Life Institute, tenutasi dal 5 al 8 gennaio 2017 presso il Asilomar Conference Grounds in California. Più di 100 thought leaders e ricercatori in doverse discipline hanno partecipato alla conferenza con l’obiettivo di discutere e formulare i principi di un’intelligenza artificiale (AI) benefica, ovvero…
Conferenza di Dartmouth
Nell’ambito dell’intelligenza artificiale, la conferenza di Dartmouth si riferisce al Dartmouth Summer Research Project on Artificial Intelligence, svoltosi nel 1956, e considerato come l’evento ufficiale che segna la nascita del campo di ricerca.
Connessionismo

Il connessionismo è un approccio alle scienze cognitive che si propone di spiegare il funzionamento della mente usando reti neurali artificiali.
Convalida incrociata
La convalida incrociata è una tecnica statistica utilizzabile in presenza di una buona numerosità del campione osservato. In particolare, la convalida incrociata cosiddetta k-fold consiste nella suddivisione dell’insieme di dati totale in k parti di uguale numerosità e, a ogni passo, la kª parte dell’insieme di dati viene a essere quella di convalida, mentre la restante parte costituisce sempre l’insieme di addestramento. Così si addestra il modello per ognuna delle k parti, evitando quindi problemi di sovradattamento, ma anche di campionamento asimmetrico del campione osservato, tipico della suddivisione dei dati in due sole parti. In altre parole, si suddivide il campione osservato in gruppi di egual numerosità, si esclude iterativamente un gruppo alla volta e si cerca di predirlo coi gruppi non esclusi, al fine di verificare la bontà del modello di predizione utilizzato.
Creatività computazionale
La creatività computazionale è una disciplina scientifica che si occupa dello studio del processo creativo tramite modelli e metodi computazionali. Più precisamente, lo studioso inglese Geraint Wiggins la definisce come «lo studio […], tramite mezzi e metodi computazionali, di comportamenti esibiti da sistemi naturali e artificiali, che sarebbero considerati creativi se esibiti da umani».
DALL-E

DALL-E, nella forma stilizzata DALL·E, è un algoritmo di intelligenza artificiale capace di generare immagini a partire da descrizioni testuali attraverso la sintografia. Sviluppato da OpenAI, viene presentato il 5 gennaio 2021.
DBSCAN
Il DBSCAN è un metodo di clustering proposto nel 1996 da Martin Ester, Hans-Peter Kriegel, Jörg Sander e Xiaowei Xu. È basato sulla densità perché connette regioni di punti con densità sufficientemente alta. DBSCAN è l’algoritmo più comunemente usato ed è anche il più citato nella letteratura scientifica.
Deep Dream

Deep Dream è un programma di elaborazione delle immagini scritto da Google. Utilizza una rete neurale convoluzionale per trovare e potenziare degli schemi all’interno di immagini tramite una pareidolia algoritmica, creando effetti allucinogeni che richiamano le sembianze di un sogno.
Design support system
Un Design Support System (DesSS) è un assistente alla progettazione basato su intelligenza artificiale e algoritmi di machine learning in grado di apprendere, correlare e interpretare i parametri di un database, rappresentanti le caratteristiche di un prodotto/servizio, al fine di proporre le caratteristiche delle nuove possibili versioni. I Design support system nascono dai Decision Support System (DSS) ottimizzati per processi di progettazione ingegneristica. Basano le loro soluzioni sui datebase inseriti al loro interno, che rielaborano ed analizzano correlarelando e interpretando i dati per le loro predizioni.
Diffusione dell’attivazione
La diffusione dell’attivazione è un metodo di ricerca per reti associative, neurali e semantiche. L’algoritmo inizia etichettando un insieme di nodi sorgente con dei pesi e propagando queste attivazioni ai nodi collegati. Solitamente questi pesi sono numeri reali che diminuiscono progressivamente (decadono) ogni volta che un nuovo arco viene percorso.
Dimostrazione automatica di teoremi
La dimostrazione automatica di teoremi o deduzione automatica, è il sottocampo più sviluppato del ragionamento automatico. L’operazione consiste nella dimostrazione di teoremi matematici da parte di un programma per computer.
Disambiguazione
La disambiguazione è il processo con il quale si precisa il significato di una parola o di un insieme di parole (frase), che denota significati diversi a seconda dei contesti, per evitare che sia ambigua.
Effetto orizzonte

L’effetto orizzonte è un problema che si crea con gli algoritmi di ricerca in profondità con interruzione programmata.
Elettrorotazione
L’elettrorotazione (ROT) è il movimento circolare di una particella polarizzata elettricamente. Simile alla rotazione del rotore di un motore elettrico, può manifestarsi quando sussiste un ritardo di fase tra il campo rotante applicato e i rispettivi processi di rilassamento dei materiali, fornendo uno strumento che permette di studiare i modelli che meglio descrivono questo comportamento e i relativi parametri.
Estrazione di caratteristiche
Nel riconoscimento di pattern e nell’elaborazione delle immagini l’estrazione di caratteristiche è una forma speciale di riduzione della dimensionalità.
Etica dell’intelligenza artificiale
L’etica dell’intelligenza artificiale è una branca dell’etica che studia le implicazioni economiche, sociali e culturali dello sviluppo dei sistemi di intelligenza artificiale (IA).
Euristica ammissibile
In informatica, un’euristica ammissibile è una funzione euristica che non sovrastima mai il costo effettivamente necessario per raggiungere l’obiettivo. Intuitivamente, una funzione ammissibile è “ottimistica”, in quanto sottostima sempre il costo effettivo.
Foresta casuale

Una foresta casuale è un classificatore d’insieme ottenuto dall’aggregazione tramite bagging di alberi di decisione L’algoritmo per la creazione di foreste casuali fu sviluppato originariamente da Leo Breiman e Adele Cutler.Le foreste casuali sono state proposte come soluzione atta a ridurre il sovradattamento del training set negli alberi di decisione.
Frame (intelligenza artificiale)
I frame sono strutture dati utilizzate nell’intelligenza artificiale nel contesto della rappresentazione della conoscenza. Il concetto è stato introdotto da Marvin Minsky nel 1974 nell’articolo A Framework for Representing Knowledge. I frame consentono di suddividere la conoscenza in sotto-strutture che rappresentano “situazioni stereotipate”.
Funzionalismo (filosofia della mente)
Il funzionalismo è una teoria della mente, sviluppata da Hilary Putnam nel 1950, in contrapposizione al riduzionismo materialista e al comportamentismo per superare la diatriba mente-corpo in filosofia della mente contemporanea.
Funzione di valutazione (euristica)
Una funzione di valutazione, nota anche come funzione di valutazione euristica o funzione di valutazione statica, è una funzione utilizzata dai programmi di gioco per stimare il valore o la bontà di una posizione in un albero di gioco.
General Problem Solver
General Problem Solver era un programma per computer creato nel 1957 da H. A. Simon, J. C. Shaw e Allen Newell, al fine di risolvere problemi generali (formalizzati). Venne creato principalmente per risolvere problemi teorici, geometrici e anche per giocare a scacchi. Venne implementato con il linguaggio IPL.
GPT-3

Generative Pre-trained Transformer 3 (GPT·3) è un modello linguistico di grandi dimensioni autoregressivo che utilizza l’apprendimento profondo per produrre testo simile al linguaggio naturale umano. “Si tratta di un algoritmo di Natural Language Generation, un settore della linguistica computazionale focalizzato sulla generazione automatica di espressioni linguistiche che siano morfologicamente, sintatticamente e semanticamente corrette e il più possibile simili all’uso umano della lingua”.
GPT-4
GPT-4 è un modello linguistico di grandi dimensioni multimodale. È il modello di quarta generazione della serie GPT creato da OpenAI, un laboratorio di ricerca sull’intelligenza artificiale con sede a San Francisco. È stato rilasciato il 14 marzo 2023 ed è attualmente disponibile tramite l’utilizzo di chiamate API e per gli utenti di ChatGPT Plus. Come altri “trasformatori”, GPT-4 è stato pre-addestrato a prevedere il prossimo token utilizzando sia dati pubblici che “dati concessi in licenza da fornitori di terze parti”, ed è stato poi perfezionato con l’apprendimento per rinforzo dal feedback umano. Non sono disponibili dati ufficiali confermati da OpenAI riguardo al numero di parametri utilizzati dal modello neurale, e nemmeno dettagli sull’infrastruttura di calcolo e l’architettura usata per eseguire GPT-4.
Grafo concettuale
Un grafo concettuale è una notazione logica basata sui grafi esistenziali di Charles Sanders Peirce e le reti semantiche usate in intelligenza artificiale. Nel primo articolo pubblicato sull’argomento, John F. Sowa usò i grafi concettuali per rappresentare gli schemi concettuali utilizzati nei sistemi di database. Il primo libro sui grafi concettuali fornì applicazioni a un’ampia gamma di argomenti in intelligenza artificiale, informatica e scienze cognitive.
Grey goo
Il grey goo è un ipotetico scenario apocalittico in cui la fine del mondo è provocata dalla nanotecnologia molecolare, dove dei robot fuori controllo e autoreplicanti consumano tutta la materia del pianeta mentre si riproducono moltiplicandosi, uno scenario noto come ecofagia.
Guida robot
Una guida robot è un sistema di visione artificiale che può guidare un robot tramite telecamere a fare un’azione.
HACKER
HACKER è un programma informatico di intelligenza artificiale per la robotica progettato da Gerald Sussman negli anni settanta. Venne scritto in linguaggio LISP ed era in grado di comandare un braccio robotico simulato, nel cosiddetto mondo dei blocchi.
Hi! PARIS

Hi! PARIS è un’organizzazione con sede a Parigi che promuove l’istruzione, la ricerca e l’innovazione nei campi dell’intelligenza artificiale (AI) e dell’analisi dei dati. Il lavoro di Hi! PARIS comprende la ricerca sulla sicurezza tecnica dell’IA e l’etica dell’IA, la difesa e il supporto per far crescere il campo di ricerca sulla sicurezza dell’IA.
Human Brain Project
Lo Human Brain Project è un progetto scientifico nel campo dell’informatica e delle neuroscienze che mira a realizzare, entro il 2023, attraverso un supercomputer, una simulazione del funzionamento completo del cervello umano.
IA-completo
L’espressione IA-completo, creata alludendo ai termini NP-completo e Turing-completo, designa un problema la cui risoluzione è considerata equivalente alla creazione di una intelligenza artificiale realistica. La comprensione completa della lingua naturale ad esempio è generalmente considerata un problema IA-completo poiché la comprensione dei testi necessita della comprensione dei concetti ad essi associati.
ImageNet
ImageNet è un’ampia base di dati di immagini, realizzata per l’utilizzo, in ambito di visione artificiale, nel campo del riconoscimento di oggetti. Il dataset consiste in più di 14 milioni di immagini che sono state annotate manualmente con l’indicazione degli oggetti in esse rappresentati e della bounding box che li delimita. Gli oggetti individuati sono stati classificati in più di 20.000 categorie: alcune categorie di oggetti frequenti, come ad esempio “pallone” o “fragola”, consistono di diverse centinaia di immagini. La base di dati con le annotazioni relative ad immagini di terze parti è gratuitamente disponibile direttamente da ImageNet, anche se le immagini non sono parte del progetto. A partire dal 2010, ogni anno viene indetta una competizione denominata ImageNet Large Scale Visual Recognition Challenge (ILSVRC): in tale occasione programmi software vengono fatti competere per classificare e rilevare correttamente oggetti e scene contenuti nelle immagini. Nell’ambito della competizione viene impiegata una lista ridotta di immagini con oggetti appartenenti a mille categorie non sovrapposte.
Impronta vocale
L’impronta vocale è l’insieme delle caratteristiche della voce di un individuo che ne permettono l’identificazione. Sebbene non vi sia accordo su quale possa essere un insieme esaustivo di tali caratteristiche, sono note alcune misurazioni in grado di caratterizzare ragionevolmente singoli individui in gruppi sufficientemente limitati di individui. Queste misurazioni vengono spesso utilizzate come misure biometriche per realizzare sistemi di autenticazione o componenti di riconoscimento del parlatore all’interno di sistemi di dialogo automatico.
Incorporamento del grafo di conoscenza

Nella disciplina dell’apprendimento delle relazioni, l’incorporamento del grafo di conoscenza, o knowledge graph embedding (KGE) in inglese, anche riferito con il nome di knowledge representation learning (KRL), o apprendimento multi relazionale è un campo dell’apprendimento automatico che si occupa di apprendere una rappresentazione a bassa dimensionalità delle…
Informazione mutua

Nella teoria della probabilità e nella teoria dell’informazione, l’informazione mutua di due variabili casuali è una quantità che misura la mutua dipendenza delle due variabili. La più comune unità di misura della mutua informazione è il bit, quando si usano i logaritmi in base 2.
Ingegneria della conoscenza
L’ingegneria della conoscenza è una disciplina che riguarda l’integrazione della conoscenza in sistemi informatici al fine di risolvere problemi complessi che tipicamente richiedono un alto livello di specializzazione umana. La disciplina si riferisce alla costruzione, manutenzione e sviluppo di sistemi basati sulla conoscenza. È correlata all’ingegneria del software ed è utilizzata in diverse aree dell’informatica quali l’intelligenza artificiale, le basi di dati, il data mining, i sistemi esperti e così via. L’ingegneria della conoscenza è anche correlata alla logica matematica e alle scienze cognitive.
Intelligenza artificiale debole
L’intelligenza artificiale debole è un’intelligenza artificiale che implementa una parte limitata della mente, o come IA ristretta, è focalizzata su un compito ristretto. Con le parole di John Searle “sarebbe utile per testare ipotesi sulle menti, ma non sarebbe in realtà una mente”. Si contrappone all’intelligenza artificiale forte, definita come una macchina con la capacità di applicare l’intelligenza a qualsiasi problema, piuttosto che a un solo problema specifico, e a volte si considera che richieda coscienza, capacità di sensazione e mente.
Intelligenza artificiale nel settore sanitario

L’intelligenza artificiale nel settore sanitario si riferisce all’applicazione dell’intelligenza artificiale (AI) per imitare la cognizione umana nell’analisi, presentazione e comprensione dei dati medici complessi, o per superare le capacità umane fornendo nuovi modi per diagnosticare, trattare o prevenire malattie. Nello specifico, l’IA è la capacità degli algoritmi informatici di arrivare a conclusioni approssimative basate esclusivamente sui dati di input.
Intelligenza artificiale simbolica
L’intelligenza artificiale simbolica indica i metodi nella ricerca sull’intelligenza artificiale che si basano su rappresentazioni “simboliche” di problemi, logica e ricerca. L’IA simbolica è stata il paradigma dominante della ricerca sull’IA dalla metà degli anni ’50 fino alla fine degli anni ’80.
Jess (informatica)
Jess è un sistema a regole implementato in Java. Utilizzato principalmente a scopo didattico, è un semplice ed intuitivo sistema utilizzato principalmente nell’ambito dell’intelligenza artificiale. Fu realizzato da Ernest J. Friedman-Hill.
K-means
L’algoritmo K-means è un algoritmo di analisi dei gruppi partizionale che permette di suddividere un insieme di oggetti in k gruppi sulla base dei loro attributi. È una variante dell’algoritmo di aspettativa-massimizzazione (EM) il cui obiettivo è determinare i k gruppi di dati generati da distribuzioni gaussiane. Si assume che gli attributi degli oggetti possano essere rappresentati come vettori, e che quindi formino uno spazio vettoriale.
K-medoids
Il K-medoids è un algoritmo di clustering partizionale correlato all’algoritmo K-means. Prevede in input un insieme di oggetti e un numero che determina quanti cluster si vogliono in output.


K-nearest neighbors
Il k-nearest neighbors, abbreviato in K-NN, è un algoritmo utilizzato nel riconoscimento di pattern per la classificazione di oggetti basandosi sulle caratteristiche degli oggetti vicini a quello considerato. In entrambi i casi, l’input è costituito dai k esempi di addestramento più vicini nello spazio delle funzionalità. L’output dipende dall’utilizzo di k-NN per la classificazione o la regressione:
Kappa di Cohen
Il Kappa di Cohen è un coefficiente statistico che rappresenta il grado di accuratezza e affidabilità in una classificazione statistica; è un indice di concordanza che tiene conto della probabilità di concordanza casuale; l’indice calcolato in base al rapporto tra l’accordo in eccesso rispetto alla probabilità di concordanza casuale e l’eccesso massimo ottenibile.
Legge sull’intelligenza artificiale
La legge sull’intelligenza artificiale è un regolamento dell’Unione europea in materia di Intelligenza artificiale che mira ad introdurre un quadro normativo e giuridico comune. L’ambito di applicazione abbraccia tutti i settori, ad eccezione di quello militare, e tutti i tipi di intelligenza artificiale.
Lisp
![]()
Lisp è una famiglia di linguaggi di programmazione con implementazioni sia compilate sia interpretate, associata nel passato ai progetti di intelligenza artificiale. È stato ideato nel 1958 da John McCarthy come linguaggio formale per studiare la computabilità di funzioni ricorsive su espressioni simboliche. È stato anche il primo linguaggio a facilitare uno stile di programmazione funzionale.
Logica dinamica
La logica dinamica è un’estensione della logica modale originariamente definita per il ragionamento di programmi e in seguito applicata a compiti più generali e complessi derivati dalla linguistica, dalla filosofia, dall’intelligenza artificiale e da altri campi.
Logica modale epistemica
La logica modale epistemica è una sottodisciplina della logica modale che si occupa del ragionamento sulla conoscenza. Mentre l’epistemologia vanta una lunga tradizione filosofica che risale all’antica Grecia, la logica epistemica ha avuto uno sviluppo molto più recente con applicazioni in molti campi, tra cui la filosofia, l’informatica teorica, l’intelligenza artificiale, l’economia e la linguistica.
Maker Faire

Per Maker Faire (fiera delle invenzioni degli artigiani digitali), anche conosciuta come #MFR, si intendono diversi eventi annuali di argomento tecnologico, le più famose delle quali sono Maker Faire di San Mateo (California) e Roma. Si tratta di una fiera annuale aperta al pubblico dedicata all’innovazione, alla tecnologia e alla creatività con uno sguardo alla robotica e all’intelligenza artificiale e allo spazio.
Mappa auto-organizzata
Una mappa auto-organizzata o mappa auto-organizzante, in inglese self-organizing map (SOM), è un tipo di organizzazione di processi di informazione in rete analoghi alle reti neurali artificiali.
Matrice di confusione
Nell’ambito del Machine learning, la matrice di confusione, detta anche tabella di errata classificazione, restituisce una rappresentazione dell’accuratezza di classificazione statistica.
John McCarthy

John McCarthy è stato un informatico statunitense che ha vinto il Premio Turing nel 1971 per i suoi contributi nel campo dell’intelligenza artificiale. È stato infatti l’inventore del termine «intelligenza artificiale» nel 1955, sebbene sia più noto per aver realizzato il linguaggio Lisp.
Metodo Otsu

Il metodo Otsu è un metodo di sogliatura automatica dell’istogramma nelle immagini digitali.
Midjourney

Midjourney è un laboratorio di ricerca e il nome del programma di intelligenza artificiale del laboratorio che crea immagini da descrizioni testuali, un sistema “text-to-image” analogo a DALL-E e a quelli presentati da Stable Diffusion.
Marvin Minsky

Marvin Lee Minsky è stato un matematico, informatico, inventore e ricercatore statunitense specializzato nel campo dell’intelligenza artificiale (IA).
MNIST database

La base di dati MNIST è una vasta base di dati di cifre scritte a mano che è comunemente impiegata come insieme di addestramento in vari sistemi per l’elaborazione delle immagini. La base di dati è anche impiegata come insieme di addestramento e di test nel campo dell’apprendimento automatico. La base di dati è stata creata rimescolando le immagini…
Modello basato sull’agente
I modelli basati sull’agente sono una classe di modelli computazionali finalizzati alla simulazione al computer di azioni e interazioni di agenti autonomi al fine di valutare i loro effetti sul sistema nel suo complesso. L’ABM combina elementi di teoria dei giochi, sistemi complessi, comportamento emergente, sociologia computazionale, sistemi multiagente. I metodi Monte Carlo sono usati per introdurre casualità. In particolare, in ecologia questi modelli vengono chiamati modelli basati sull’individuo (IBM) e gli individui in un modello IBM possono essere più semplici rispetto agli agenti completamente autonomi degli ABM. Una recente revisione della letteratura sui modelli basati sugli individui, basati sugli agenti, e sui sistemi multi-agente mostra che gli ABM sono usati in domini scientifici non correlati al calcolo come la biologia, l’ecologia e le scienze sociali. La modellizzazione basata sull’agente è correlata ma distinta dal concetto di sistema multi-agente o simulazione multi-agente, in quanto l’obiettivo del primo è di cercare informazioni esplicative sul comportamento collettivo degli agenti che obbediscono a semplici regole, tipicamente in sistemi naturali, a differenza del secondo, il cui obiettivo è di progettare agenti o risolvere specifici problemi pratici o ingegneristici.
Modello BDI
Il modello BDI consente di rappresentare le caratteristiche e le modalità di raggiungimento di un obiettivo (goal) in un sistema costruito secondo i paradigmi degli agenti software.
Motore inferenziale
In informatica, un motore inferenziale è un algoritmo che simula le modalità con cui la mente umana trae delle conclusioni logiche attraverso il ragionamento. Fa parte dei software detti “sistemi esperti”.
Multilateral Instrument Matching Database
Il Multilateral Instrument Matching Database, anche detto Matching Database, è un prototipo di intelligenza artificiale creato dall’OCSE per l’applicazione della Convenzione multilaterale anti-BEPS.
Musica e intelligenza artificiale
Per musica e intelligenza artificiale si intende il contributo dato dall’IA nell’ambito della musica. La ricerca sull’intelligenza artificiale (IA) ha avuto un impatto sulla diagnosi medica, sulla finanza, sul controllo dei robot e su molti altri campi, compreso quello musicale. L’intelligenza artificiale e la musica (AIM) sono state a lungo un argomento comune in numerose conferenze e workshop, tra cui l’International Computer Music Conference, la Computing Society Conference e la International Joint Conference on Artificial Intelligence. In effetti, la prima Conferenza Internazionale sulla Computer Music è stata l’ICMC nel 1974, presso la Michigan State University. La ricerca attuale include l’applicazione dell’IA nella composizione musicale, performance, teoria ed elaborazione del suono digitale.
Negamax
Il negamax è una piccola variante dell’algoritmo minimax che si basa sulle proprietà dei giochi a somma zero con due giocatori.
Negascout
Il NegaScout o Ricerca a variazione principale è un algoritmo negamax che in alcuni casi può essere più veloce della potatura alfa-beta. Come quest’ultima, il Negascout è un algoritmo per la ricerca del nodo di valore minimo in un dato albero; è dominante sull’algoritmo alfa-beta, cioè non visiterà mai un nodo che l’alfa-beta avrebbe potato, però questa caratteristica esige un accurato ordinamento dell’albero da esaminare per essere vantaggiosa, per cui la sua adozione deve essere decisa valutando la struttura del programma e le caratteristiche del problema da affrontare.
OpenAI
OpenAI è un laboratorio di ricerca sull’intelligenza artificiale costituito dalla società no-profit OpenAI, Inc. e dalla sua sussidiaria for-profit OpenAI, L.P. A settembre 2024 è emerso in una intervista al CEO Sam Altman che è in corso la piena trasformazione di OpenAI in una società a scopo di lucro. L’obiettivo della ricerca di OpenAI è promuovere e sviluppare un’intelligenza artificiale amichevole in modo che l’umanità possa trarne beneficio.
Operatore di Roberts
Il filtro di Roberts è stato uno dei primi filtri digitali utilizzato nell’ambito della visione artificiale per estrarre i contorni da un’immagine digitalizzata. Esso sfrutta la somma dei quadrati del peso associato ai pixel dell’immagine, convolvendola con una delle due seguenti matrici:
oppure

Operatore di Sobel

L’operatore di Sobel è un algoritmo usato per elaborare immagini digitali, in particolare per effettuare il riconoscimento dei contorni. Dal punto di vista tecnico è un operatore differenziale, che calcola un valore approssimato del gradiente di una funzione che rappresenta la luminosità dell’immagine. In ogni punto dell’immagine, l’operatore di Sobel può corrispondere al vettore gradiente…
Optical mark recognition
L’Optical Mark Recognition è il processo di cattura di informazioni tramite il riconoscimento di marcature in punti predefiniti di una pagina.
Ottimizzazione minima sequenziale
L’Ottimizzazione minima sequenziale è un algoritmo per risolvere efficientemente il problema di ottimizzazione che emerge durante l’addestramento di una Macchine a vettori di supporto. Fu inventato da John Platt nel 1998 al laboratorio Microsoft Research di Redmond. L’Ottimizzazione minima sequenziale è implementata nella famosa libreria software libsvm.
Overfitting

In statistica e in informatica, si parla di overfitting o sovradattamento quando un modello statistico molto complesso si adatta ai dati osservati perché ha un numero eccessivo di parametri rispetto al numero di osservazioni.
Paradosso di Moravec
Il paradosso di Moravec è la scoperta da parte dei ricercatori di intelligenza artificiale e robotica che, contrariamente alle ipotesi tradizionali, il ragionamento di alto livello richiede pochissimo calcolo, ma le capacità sensomotorie di basso livello richiedono enormi risorse computazionali.
Particle Swarm Optimization

In informatica, l’ottimizzazione con sciami di particelle, nota anche come particle swarm optimization (PSO), è un algoritmo di ottimizzazione e appartiene ad una particolare classe di algoritmi utilizzati in diversi campi, tra cui l’intelligenza artificiale. È un metodo euristico di ricerca ed ottimizzazione, ispirato al movimento degli sciami.
Perplexity.ai
Perplexity AI è un motore di ricerca basato su chat bot con intelligenza artificiale generativa che risponde alle query utilizzando testo predittivo in linguaggio naturale. All’inizio del 2024 conta circa 10 milioni di utenti mensili.
Personalità elettronica
Il termine personalità elettronica è stato utilizzato per la prima volta in una bozza concernente norme di diritto civile sulla robotica, da parte della Commissione Europea il 31 maggio del 2016. Proponendo di conferire la personalità elettronica ai robot più sofisticati, i robot autonomi, si riconoscono diritti e doveri specifici in capo a questi, compreso l’onere di risarcire danni causati dall’operato di queste macchine. Si va così a riconoscere la personalità elettronica ai robot nei casi in cui prendano autonome decisioni o interagiscano con terze parti in modo indipendente.
Personality computing
L’elaborazione della personalità o personality computing è un campo di ricerca correlato all’intelligenza artificiale e alla psicologia della personalità che studia la personalità mediante tecniche computazionali le quali utilizzano diverse fonti per estrapolare dati, tra cui: testo, multimedia e social network.
Phraser
Phraser è un software che utilizza algoritmi di apprendimento automatico per aiutare a creare descrizioni in linguaggio naturale per le reti neurali.
Pianificazione automatica
La pianificazione automatica è una branca dell’intelligenza artificiale e, in particolare, rappresenta un’attività di problem solving. L’attività di pianificazione automatica consiste nel concepire in maniera dinamica una certa sequenza di azioni che fanno sì che un obiettivo dato, non inizialmente verificato, venga raggiunto, partendo da una situazione iniziale. Le più comuni applicazioni della pianificazione automatica sono lo scheduling, la robotica e il pilotaggio di veicoli senza equipaggio.
Premio Loebner
Il Premio Loebner è una competizione annuale d’intelligenza artificiale svolta nell’Università di Reading. Viene premiato il chat bot in grado di ottenere il punteggio migliore in uno scenario da test di Turing. La giuria distingue le risposte del programma dall’essere umano.
Problema di soddisfacimento di vincoli
Molti problemi nell’ambito dell’Intelligenza Artificiale sono classificabili come Problemi di Soddisfacimento di Vincoli ; fra questi citiamo problemi di complessità combinatorica, di allocazione di risorse, pianificazione e ragionamento temporale. Questi problemi possono essere risolti efficientemente attraverso tecniche ben note di risoluzione di CSP.
Programmazione evolutiva
La programmazione evolutiva è un paradigma di programmazione sviluppato principalmente da David B. Fogel da inquadrare all’interno del campo dell’informatica noto come computazione evolutiva. Il suo studio è approfondito all’interno dei settori dell’intelligenza artificiale e delle tecniche di soft computing.
Programmazione genetica
La programmazione genetica, dall’inglese genetic programming (GP), è una metodologia di programmazione automatizzata, ispirata dall’evoluzione biologica, per scoprire programmi informatici che svolgano in maniera ottimale un determinato compito. È una particolare tecnica di apprendimento automatico che usa un algoritmo evolutivo per ottimizzare una popolazione di programmi di computer secondo un paesaggio adattativo determinato dall’abilità del programma di arrivare a un risultato computazionalmente valido.
Programmazione logica abduttiva
La Programmazione Logica Abduttiva è una sottoarea della programmazione logica che inserisce nella programmazione logica regole di inferenza basate sulla abduzione.
Programmazione logica induttiva
La programmazione logica induttiva è una sottoarea dell’apprendimento automatico che rappresenta la sua confluenza con la programmazione logica.
Psicologia cognitiva
La psicologia cognitiva, anche detta cognitivismo, è una branca della psicologia applicata allo studio dei processi cognitivi, teorizzata a partire dagli anni 1960, che ha come obiettivo lo studio dei processi mentali mediante i quali le informazioni vengono acquisite dal sistema cognitivo, elaborate, memorizzate e recuperate. La cosiddetta “rivoluzione cognitiva” rimpiazzò l’orientamento teorico allora prevalente, il comportamentismo, che invece teorizzava la non indagabilità dei processi mentali, e l’associazione diretta tra stimolo e risposta.
Question answering
Nell’information retrieval, il question answering (QA) consiste nel rispondere automaticamente a una domanda espressa in una lingua naturale. Per trovare la risposta a una domanda, un programma di QA può utilizzare una base di conoscenza o una raccolta di documenti in lingua naturale.
Ragionamento automatico
Il ragionamento automatico è un’area dell’informatica dedicata alla comprensione dei diversi aspetti del ragionamento al fine di creare dei programmi che permettano ai computer di ragionare in modo parzialmente o addirittura completamente automatico. L’area è considerata un sottocampo dell’intelligenza artificiale, sebbene abbia forti connessioni con l’informatica teorica e persino con la filosofia.
Ragionamento continuo
Il ragionamento continuo è una metodologia di ragionamento automatico che sfrutta la composizionalità per analizzare sistemi di larga scala in modo differenziale. Il ragionamento continuo si concentra sull’analisi delle ultime modifiche introdotte nel sistema e riutilizza i risultati di analisi precedenti per quanto possibile. L’obiettivo del ragionamento continuo è quello di contenere l’elevata complessità computazionale dei problemi su sistemi di larga scala attraverso la risoluzione di istanze più piccole dei problemi da risolvere, ovvero risolvendo istanze che considerino principalmente ciò che è cambiato nel sistema dopo l’ultima analisi effettuata.
Ragionatore automatico
Un ragionatore automatico è un software in grado di svolgere dei ragionamenti su delle basi di conoscenza adeguatamente formalizzate.
Ratio Club
Il Ratio Club è stato un piccolo gruppo informale di giovani psicologi, fisiologi, matematici ed ingegneri britannici che, nei primi anni del secondo dopoguerra, si incontravano per discutere dei problemi di interesse della cibernetica, che in quegli anni viveva i primi anni di forte espansione.
ReCAPTCHA
reCAPTCHA Inc. è un sistema CAPTCHA ideato nel 2007 da un gruppo di ricerca della Carnegie Mellon University e rilevato da Google nel 2009. Originariamente concepito per semplificare la digitalizzazione di testi e manoscritti, esso consente ai web host di distinguere gli accessi ai propri siti web effettuati da parte di esseri umani da quelli effettuati tramite procedure automatizzate. Ad ottobre 2022 detiene da solo il 97% delle quote di mercato relativo ai servizi per l’identificazione automatica tramite CAPTCHA degli utenti che accedono ai siti web.
Registrazione d’immagini

Nell’elaborazione digitale delle immagini e nella visione artificiale, gli insiemi di dati acquisiti in base al campionamento della stessa scena oppure di un oggetto in movimento relativo o da diverse prospettive, si troveranno in sistemi di coordinate diversi. La registratura d’immagini è quel processo che permette la trasformazione di differenti insiemi di dati presenti in diversi insiemi di coordinate in un sistema dove ogni coordinata spaziale corrisponde, evidenziando così ogni possibile cambiamento in dimensioni, forma o posizione. La registratura è necessaria per poter confrontare o integrare i dati ottenuti da diverse misure.
Responsabilità giuridica dell’intelligenza artificiale
Qualsiasi entità dotata di intelligenza artificiale con accesso al mondo reale, incluse autovetture autonome e robot, può causare danni e lesioni; questo solleva interrogativi sulla responsabilità giuridica dell’intelligenza artificiale, sia sotto il profilo della responsabilità civile, sia della responsabilità penale.
Rete bayesiana
Una rete bayesiana è un modello grafico probabilistico che rappresenta un insieme di variabili stocastiche con le loro dipendenze condizionali attraverso l’uso di un grafo aciclico diretto (DAG). Per esempio una rete Bayesiana potrebbe rappresentare la relazione probabilistica esistente tra i sintomi e le malattie. Dati i sintomi, la rete può essere usata per calcolare la probabilità della presenza di diverse malattie.
Rete generativa avversaria
Una rete generativa avversaria è una classe di metodi di apprendimento automatico, introdotta per la prima volta da Ian Goodfellow, in cui due reti neurali vengono addestrate in maniera competitiva nel contesto di un gioco a somma zero. Questo tipo di framework permette alla rete neurale di apprendere come generare nuovi dati aventi la stessa distribuzione dei dati usati in fase di addestramento. Ad esempio, è possibile ottenere una rete neurale in grado di generare volti umani iperrealistici, come dimostrato nel 2018 da NVIDIA, azienda produttrice di GPU.
Rete neurale ricorrente

Una rete neurale ricorrente o RNN è una classe di rete neurale artificiale che include neuroni collegati tra loro in un ciclo. Tipicamente i valori di uscita di uno strato di un livello superiore sono utilizzati in ingresso di uno strato di livello inferiore. Quest’interconnessione tra strati permette l’utilizzo di uno degli strati come memoria di stato, e consente, fornendo in ingresso una…
Rete semantica

Una rete semantica è una forma di rappresentazione della conoscenza. È un grafo formato da vertici, che rappresentano concetti, e archi, che rappresentano relazioni semantiche tra i concetti. Le reti semantiche sono un tipo comune di dizionario leggibile da una macchina.
Riconoscimento dei contorni

Il riconoscimento dei contorni è utilizzato allo scopo di marcare i punti di un’immagine digitale in cui l’intensità luminosa cambia bruscamente. Bruschi cambiamenti delle proprietà di un’immagine sono di solito il sintomo di eventi o cambiamenti importanti del mondo fisico di cui le immagini sono la…
Riconoscimento della scrittura

Per riconoscimento della scrittura si intende una funzionalità presente specialmente nei PDA, nei tablet PC e nei computer dotati di tavoletta grafica, che permette all’utente di trasformare immagini o inchiostro digitale in “testo battuto a tastiera”.
Ricottura quantistica

La ricottura quantistica o quantum annealing in matematica è un metodo generale per trovare il minimo globale di una data funzione su un insieme di soluzioni candidate, mediante un processo analogo alle fluttuazioni quantistiche. I qubit si posizionano per raggiungere uno stato di minima energia assoluta,…
Ricottura simulata
La ricottura simulata è una strategia utilizzata per risolvere problemi di ottimizzazione, che mira a trovare un minimo globale quando si è in presenza di più minimi locali.
Roborace
Roborace sarà un campionato di corse motoristiche, con vetture alimentate elettricamente a guida autonoma.
Robotic process automation
La robotic process automation (RPA) è l’automazione di processi lavorativi utilizzando software “intelligenti”, che possono eseguire in modo automatico le attività ripetitive degli operatori, imitandone il comportamento e interagendo con gli applicativi informatici nello stesso modo dell’operatore stesso.
John Searle

John Rogers Searle è un filosofo statunitense.
Selezione delle caratteristiche
Nel riconoscimento di pattern e nell’elaborazione delle immagini la selezione delle caratteristiche è una forma speciale di riduzione della dimensionalità di un determinato dataset.
Semantic Pointer Architecture Unified Network
Semantic Pointer Architecture Unified Network (Spaun) è un’architettura connessionista biologicamente ispirata ideata da Chris Eliasmith del Center for Theoretical Neuroscience dell’Università di Waterloo. È un sistema di 2,5 milioni di neuroni artificiali organizzati in sottosistemi che assomigliano a specifiche regioni del cervello, come la corteccia prefrontale, i gangli della base e il talamo. È implementato usando il framework computazionale Nengo.
SHRDLU
SHRDLU è un programma di comprensione del linguaggio naturale sviluppato da Terry Winograd al MIT nel periodo 1968-1970. È stato scritto nei linguaggi di programmazione Micro Planner e Lisp su un computer DEC PDP-6 e un terminale grafico DEC. Modifiche successive sono state apportate al programma nei laboratori di computer grafica dell’Università dello Utah, aggiungendo una renderizzazione 3D del mondo di SHRDLU.
Singolarità tecnologica

Una singolarità tecnologica è, nella futurologia, un punto congetturato nello sviluppo di una civiltà, in cui il progresso tecnologico accelera oltre la capacità di comprendere e prevedere degli esseri umani. La singolarità può, più specificamente, riferirsi all’avvento di un’intelligenza superiore a quella umana, e ai progressi tecnologici che, a cascata, si presume seguirebbero da un tale evento, salvo che non intervenga un importante aumento artificiale delle facoltà intellettive di ciascun individuo. Se una singolarità possa mai avvenire, è materia di discussione.
Sistema esperto
Un sistema esperto è un programma che cerca di riprodurre le prestazioni di una o più persone esperte in un determinato campo di attività, ed è un’applicazione o una branca dell’intelligenza artificiale.
Sistema immunitario artificiale
Il metodo del sistema immunitario artificiale è un tipo di algoritmo di ottimizzazione ispirato ai principi e ai processi del sistema immunitario degli esseri viventi. In particolar modo gli algoritmi di questo genere sfruttano le caratteristiche di memoria ed esperienza per risolvere i problemi studiati. Sono accoppiati all’intelligenza artificiale e strettamente correlati con gli algoritmi genetici.
Sistema multiagente
Un sistema multiagente o è un insieme di agenti situati in un certo ambiente ed interagenti tra loro mediante una opportuna organizzazione. Un agente è cioè un’entità caratterizzata dal fatto di essere, almeno parzialmente, autonoma, sia essa un programma informatico, un robot, un essere umano, e così via.
Sistemi basati sulla conoscenza
Un sistema basato sulla conoscenza è essenzialmente un programma capace di ragionare usando una base di conoscenza al fine di risolvere problemi complessi. Con tali termini ci si può riferire a una vasta gamma di sistemi.
Soft computing

Le tecniche di soft computing si prefiggono di valutare, decidere, controllare e calcolare in un ambito impreciso e vago emulando e utilizzando la capacità degli esseri umani di eseguire le suddette attività sulla base della loro esperienza. Il soft computing si avvale delle caratteristiche delle sue tre principali branche:
- la possibilità di modellare e di controllare
SpiNNaker
SpiNNaker (Spiking Neural Network Architecture) è un’architettura per computer multi core progettata dal gruppo di ricerca di tecnologie per processori avanzati (APT) alla Scuola di Scienze informatiche dell’Università di Manchester (School of Computer Science, University of Manchester) condotto da Steve Furber, per simulare il cervello umano (Human Brain Project). Usa un milione di processori ARM in una piattaforma di calcolo altamente parallelizzata basata sulle reti neurali spike (reti neurali a impulso)…
Stable Diffusion

Stable Diffusion è un modello di apprendimento automatico profondo pubblicato nel 2022, utilizzato principalmente per generare immagini dettagliate a partire da descrizioni di testo, sebbene possa essere applicato anche ad altre attività come la pittura, la pittura esterna e la generazione di traduzioni da immagine a immagine guidate da un prompt di testo.
Stochastic neural analog reinforcement calculator
Lo SNARC è considerato il primo elaboratore a rete neurale, progettato da Marvin Lee Minsky e da Dean Edmonds.
STRIPS
Nell’intelligenza artificiale, STRIPS è un pianificatore automatico sviluppato nel 1971 da Richard Fikes e Nils Nilsson dell’università di Stanford. Il sistema sfrutta la logica delle proposizioni espansa con i predicati ed il meccanismo di ricerca nello spazio degli stati, per ottenere una possibile sequenza di azioni che, se eseguite, provocano il raggiungimento di uno stato finale del mondo a partire da uno iniziale.
Tabu search
La Tabu Search è una tecnica meta-euristica utilizzata per la soluzione di numerosi problemi di ottimizzazione, tra cui problemi di scheduling e routing, problemi su grafi e programmazione intera.
Tensor Processing Unit

Una tensor processing unit (TPU) è un acceleratore IA costituito da un circuito ASIC sviluppato da Google per applicazioni specifiche nel campo delle reti neurali. La prima tensor processing unit è stata presentata nel maggio del 2016 in occasione della Google I/O; la società specificò che le TPU erano già impiegate all’interno dei propri data center da oltre un anno. Il circuito è stato…
Tensor voting
Il tensor voting è un algoritmo utilizzato nella visione artificiale, che permette di inferire informazioni riguardanti le strutture geometriche descritte da un insieme parziale di dati. Si ispira ai principi della Gestalt riguardanti il sistema visivo animale: l’individuo riceve continuamente informazioni parziali, informazioni errate o corrotte dal rumore, ma ha la capacità di distinguere il rumore, per poterlo eliminare, e di ricostruire le informazioni mancanti.
Demetri Terzopoulos

Demetri Terzopoulos FRS, FRSC è un informatico greco con cittadinanza statunitense naturalizzato canadese, è Distinguished Professor e Chancellor’s Professor of Computer Science presso la Henry Samueli School of Engineering and Applied Science dell’Università della California, Los Angeles, dove dirige il Laboratorio dell’UCLA di Computer Graphics & Vision..
Test di Turing

Il test di Turing è un criterio per determinare se una macchina è in grado di esibire un comportamento intelligente, suggerito da Alan Turing nell’articolo Computing machinery and intelligence apparso nel 1950 sulla rivista Mind.
Text categorization
La classificazione del testo è, nell’intelligenza artificiale, un’attività che si occupa di classificare testi digitali espressi in una lingua naturale assegnando in maniera automatica collezioni di documenti a una o più classi appartenenti a un “insieme di classi” predefinito.
Tierra (simulazione)
Tierra è una simulazione su computer sviluppata dall’ecologista Thomas S. Ray all’inizio degli anni 90 i cui programmi competono per l’utilizzo di tempo processore CPU e della memoria centrale. I programmi in Tierra possono evolvere, possono mutare, si auto riparano e si ricombinano. Tierra è un classico esempio di modello di vita artificiale; nella metafora di Tierra i singoli programmi possono essere considerati come organismi che competono per l’energia e le risorse.
Training e test set
Nell’apprendimento automatico un training set è un insieme di esempi ad ognuno dei quali è associata una risposta, il valore di un attributo-obiettivo, ossia un valore categorico, cioè una classe, o un valore numerico. Tali esempi vengono utilizzati per addestrare un modello predittivo supervisionato capace di determinare il valore-obiettivo per nuovi esempi. Un modello addestrato può essere valutato su un nuovo insieme di esempi, il test set, non utilizzati in fase di addestramento.
Trasformata di Hough
La trasformata di Hough è una tecnica di estrazione utilizzata nel campo dell’elaborazione digitale delle immagini. Nella sua forma classica si basa sul riconoscimento delle linee di un’immagine, ma è stata estesa anche al riconoscimento di altre forme arbitrariamente definite. Fu scoperta da Richard Duda e Peter Hart nel 1972, ed è oggi utilizzata universalmente. La trasformata di Hough è molto conosciuta nella comunità degli specialisti di Computer vision, specialmente da quando Dana H. Ballard ha pubblicato un articolo dal titolo: “Generalizzazione della trasformata di Hough per il riconoscimento di forme arbitrariamente definite”.
Uncanny valley
L’uncanny valley, traducibile come valle perturbante, è un’ipotesi presentata nel 1970 dallo studioso di robotica nipponico Masahiro Mori e pubblicata nella rivista Energy. La ricerca analizza sperimentalmente come la sensazione di familiarità e di piacevolezza sperimentata da un campione di persone e generata da robot e automi antropomorfi possa aumentare al crescere della loro somiglianza con la figura umana, fino ad un punto in cui l’estremo realismo rappresentativo produce però un brusco calo delle reazioni emotive positive, a causa della non concreta realisticità, destando sensazioni spiacevoli come repulsione e inquietudine paragonabili al perturbamento.
Visual servoing
Visual servoing, abbreviato con VS, anche conosciuto come asservimento visivo basato sull’immagine, è una tecnica di controllo in retroazione che usa come feedback l’informazione estratta dai sensori visivi per controllare il movimento di un robot. Uno dei primi articoli che ha introdotto il Visual Servoing fu pubblicato dai laboratori SRI International Labs. Un primo tutorial sul Visual Servoing fu pubblicato nel 1996 da S. A. Hutchinson, G. D. Hager e P. I. Corke, mentre più recenti tutorial sono stati pubblicati nel 2006 e nel 2007 da F. Chaumette e S. Hutchinson.
Vita artificiale
La vita artificiale è lo studio della vita mediante l’uso di analoghi costruiti dall’uomo dei sistemi viventi. L’informatico Christopher Langton ha coniato il termine verso la fine degli anni ottanta quando ha tenuto la prima “Conferenza Internazionale sulla Sintesi e Simulazione dei Sistemi Viventi” presso il Laboratorio Nazionale di Los Alamos, nel 1987.
Watson (intelligenza artificiale)

Watson è un sistema di intelligenza artificiale, in grado di rispondere a domande espresse in un linguaggio naturale, sviluppato all’interno del progetto DeepQA di IBM a cura del team di ricerca diretto da David Ferrucci. Il nome è stato scelto in onore del primo presidente dell’IBM Thomas J. Watson.
Web research
Con il termine web research o web listening o web monitoring si indica un’azione di ricerca di mercato o sondaggio d’opinione che consiste nell’ascolto o monitoraggio del web, intesa come intercettazione, misurazione, analisi e interpretazione di quanto viene scritto in rete su un dato argomento, prodotto o servizio.
Web semantico
Il web semantico è un’estensione del World Wide Web in cui i documenti pubblicati sono associati ad informazioni e dati (metadati) che ne specificano il contesto semantico in un formato adatto all’interrogazione e all’interpretazione e, più in generale, all’elaborazione automatica.
Word2vec
Word2vec è un insieme di modelli che sono utilizzati per produrre word embedding, il cui pacchetto fu originariamente creato in C da Tomas Mikolov, poi implementato anche in Python e Java. Word2vec è una semplice rete neurale artificiale a due strati progettata per elaborare il linguaggio naturale, l’algoritmo richiede in ingresso un corpus e restituisce un insieme di vettori che rappresentano la distribuzione semantica delle parole nel testo. Per ogni parola contenuta nel corpus, in modo univoco, viene costruito un vettore in modo da rappresentarla come un punto nello spazio multidimensionale creato. In questo spazio le parole saranno più vicine se riconosciute come semanticamente più simili. Per capire come Word2vec possa produrre word embedding è necessario comprendere le architetture CBOW e Skip-Gram.





I’m extremely inspired with your writing talents and also with the layout on your blog. Is that this a paid subject or did you customize it your self? Anyway stay up the excellent high quality writing, it is rare to peer a great blog like this one these days!