Apprendimento automatico: cos’è, tutti gli argomenti
Argomenti sull’Apprendimento automatico
Apprendimento automatico

L’apprendimento automatico è una branca dell’intelligenza artificiale che raccoglie metodi sviluppati negli ultimi decenni del XX secolo in varie comunità scientifiche, sotto diversi nomi quali: statistica computazionale, riconoscimento di pattern, reti neurali artificiali, filtraggio adattivo, teoria dei sistemi dinamici, elaborazione delle immagini, data mining, algoritmi adattivi, ecc; che utilizza metodi…
DeepL Translator
![]()
DeepL Translator è un servizio di traduzione gratuito multilingue, alimentato dalla base di conoscenza di Linguee, servizio creato dalla stessa azienda, DeepL GmbH. Al 2023, il portale supporta 31 lingue per un totale di 552 accoppiamenti.
Incorporamento del grafo di conoscenza

Nella disciplina dell’apprendimento delle relazioni, l’incorporamento del grafo di conoscenza, o knowledge graph embedding (KGE) in inglese, anche riferito con il nome di knowledge representation learning (KRL), o apprendimento multi relazionale è un campo dell’apprendimento automatico che si occupa di apprendere una rappresentazione a bassa dimensionalità delle…
Adversarial machine learning
Adversarial machine learning è una serie di tecniche volte a compromettere il corretto funzionamento di un sistema informatico che faccia uso di algoritmi di apprendimento automatico, tramite la costruzione di input speciali in grado di ingannare tali algoritmi: più nello specifico, lo scopo di tali tecniche è quello di causare la classificazione errata in uno di questi algoritmi. Inoltre, nel caso..
Albero di decisione

Nella teoria delle decisioni, un albero di decisione è un grafo di decisioni e delle loro possibili conseguenze, utilizzato per creare un ‘piano di azioni’ (plan) mirato ad uno scopo (goal). Un albero di decisione è costruito al fine di supportare l’azione decisionale.
Algoritmo di Baum-Welch
L’algoritmo di Baum-Welch viene usato in elettrotecnica, informatica, informatica statistica e bioinformatica per trovare i parametri incogniti di un modello di Markov nascosto (HMM). Si avvale di un algoritmo forward-backward che prende il nome di Leonard Esau Baum e Lloyd Richard Welch.
Algoritmo EM
In statistica, un algoritmo di aspettazione-massimizzazione o algoritmo expectation-maximization (EM) è un metodo iterativo per trovare stime (locali) di massima verosimiglianza dei parametri di modelli statistici che dipendono da variabili latenti. L’iterazione di EM alterna l’esecuzione di un passo detto expectation (E), che crea una funzione per il valore atteso della verosimiglianza logaritmica calcolata usando la stima dei parametri corrente, e un passo detto maximization (M), che calcola nuove stime dei parametri massimizzando la funzione di verosimiglianza logaritmica attesa trovata al passo E. Tali stime dei parametri possono poi essere usate per determinare la distribuzione delle variabili latenti al passo E dell’iterata successiva.
Algoritmo genetico
Un algoritmo genetico è un algoritmo euristico utilizzato per tentare di risolvere problemi di ottimizzazione per i quali non si conoscono altri algoritmi efficienti di complessità lineare o polinomiale. L’aggettivo “genetico”, ispirato al principio della selezione naturale ed evoluzione biologica teorizzato nel 1859 da Charles Darwin, deriva dal fatto che, al pari del modello evolutivo darwiniano che trova spiegazioni nella branca della biologia detta genetica, gli algoritmi genetici attuano dei meccanismi concettualmente simili a quelli dei processi biochimici scoperti da questa scienza.
AlphaFold
AlphaFold è un programma di intelligenza artificiale sviluppato da DeepMind (Alphabet/Google) per predire la struttura tridimensionale delle proteine. Il programma è stato progettato come un sistema di deep learning.
AlphaGo Zero
AlphaGo Zero è una versione del programma per giocare a Go di DeepMind, AlphaGo. Il team di AlphaGo ha pubblicato un articolo sulla rivista Nature il 19 ottobre 2017, introducendo AlphaGo Zero, una versione creata senza utilizzare informazioni provenienti da partite tra giocatori umani e più potente di qualsiasi versione precedente. Giocando contro sé stesso, AlphaGo Zero ha superato la forza della versione di AlphaGo che aveva affrontato Lee Se-dol in tre giorni vincendo 100 partite a 0, ha raggiunto il livello di AlphaGo Master in 21 giorni e ha superato tutte le vecchie versioni in 40 giorni.
AlphaZero
AlphaZero è un algoritmo di intelligenza artificiale basato su tecniche di apprendimento automatico sviluppato da Google DeepMind. È una generalizzazione di AlphaGo Zero, predecessore sviluppato specificamente per il gioco del go e a sua volta evoluzione di AlphaGo, primo software capace di raggiungere prestazioni sovrumane nel gioco del go. Analogamente ad AlphaGo Zero, impiega la ricerca ad albero Monte Carlo (MCTS) guidata da una rete neurale convoluzionale profonda addestrata per rinforzo.
Amazon Alexa

Amazon Alexa, detto semplicemente Alexa, è un assistente virtuale sviluppato dall’azienda statunitense Amazon, utilizzato per la prima volta nei dispositivi Amazon Echo e Amazon Echo Dot.
Apprendimento bayesiano
L’apprendimento bayesiano è un metodo computazionale di apprendimento basato sul calcolo delle probabilità, che può fornire predizioni probabilistiche sfruttando i principi del teorema di Bayes per realizzare un apprendimento non supervisionato.
Apprendimento d’insieme
In statistica e apprendimento automatico, con apprendimento d’insieme si intendono una serie di metodi che usano molteplici modelli o algoritmi per ottenere una migliore prestazione predittiva rispetto a quella ottenuta dagli stessi modelli applicati singolarmente. A differenza dell’insieme della meccanica statistica, che si ritiene infinito, tale insieme di modelli alternativi è concreto e finito.
Apprendimento di ontologie
L’apprendimento di ontologie consiste nell’estrazione (semi-)automatica di concetti e relazioni rilevanti a partire da una collezione di documenti o altri insiemi di dati al fine di creare un’ontologia.
Apprendimento federato
L’apprendimento federato è una tecnica di apprendimento automatico che permette di addestrare un algoritmo attraverso l’utilizzo di dispositivi decentralizzati o server che mantengono i dati, senza la necessità di scambiare i dati stessi. Questo approccio si oppone alle tradizionali tecniche di apprendimento automatico centralizzate dove i dati vengono caricati su un server, o ai più tradizionali metodi decentralizzati che assumono che i dati locali sono distribuiti in modo identico.
Apprendimento non supervisionato
L’apprendimento non supervisionato è una tecnica di apprendimento automatico che consiste nel fornire al sistema informatico una serie di input che egli riclassificherà e organizzerà sulla base di caratteristiche comuni per cercare di effettuare ragionamenti e previsioni sugli input successivi. Al contrario dell’apprendimento supervisionato, durante l’apprendimento vengono forniti all’apprendista solo esempi non annotati, in quanto le classi non sono note a priori ma devono essere apprese automaticamente.
Apprendimento per rinforzo
L’apprendimento per rinforzo è una tecnica di apprendimento automatico che punta a realizzare agenti autonomi in grado di scegliere azioni da compiere per il conseguimento di determinati obiettivi tramite interazione con l’ambiente in cui sono immersi.
Apprendimento profondo
L’apprendimento profondo è quel campo di ricerca dell’apprendimento automatico e dell’intelligenza artificiale che si basa su diversi livelli di rappresentazione, corrispondenti a gerarchie di caratteristiche di fattori o concetti, dove i concetti di alto livello sono definiti sulla base di quelli di basso.
Apprendimento supervisionato
L’apprendimento supervisionato è una tecnica di apprendimento automatico che mira a istruire un sistema informatico in modo da consentirgli di elaborare automaticamente previsioni sui valori di uscita di un sistema rispetto a un input sulla base di una serie di esempi ideali, costituiti da coppie di input e di output, che gli vengono inizialmente forniti.
BERT
BERT, acronimo di Bidirectional Encoder Representations from Transformers, è un modello di apprendimento automatico basato su trasformatori utilizzato nell’elaborazione del linguaggio naturale (NLP). BERT è stato creato e pubblicato nel 2018 da Jacob Devlin e dai suoi colleghi di Google. Nel 2019, Google annunciò di aver cominciato a utilizzare BERT per il suo motore di ricerca, e verso la fine del 2020 pressoché ogni richiesta in lingua inglese utilizzava BERT. Un’analisi pubblicata nel 2020 in letteratura concluse che BERT diventò il riferimento per gli esperimenti di NLP in poco più di un anno, contando oltre 150 pubblicazioni che provavano a migliorare o ad analizzare il modello.
Bias induttivo
Nell’apprendimento automatico, il bias induttivo di un algoritmo è l’insieme di assunzioni che il classificatore usa per predire l’output dati gli input che esso non ha ancora incontrato.
Boosting
Il boosting è una tecnica di machine learning che rientra nella categoria dell’Apprendimento ensemble. Nel boosting più modelli vengono generati consecutivamente dando sempre più peso agli errori effettuati nei modelli precedenti. In questo modo si creano modelli via via più “attenti” agli aspetti che hanno causato inesattezze nei modelli precedenti, ottenendo infine un modello aggregato avente migliore accuratezza di ciascun modello che lo costituisce.
Campo casuale di Markov

Un campo casuale di Markov, detto anche rete di Markov, è un insieme di variabili casuali che verificano la proprietà di Markov rispetto a un grafo non orientato che rappresenta le dipendenze fra tali variabili. In altre parole, un campo aleatorio si dice markoviano se verifica la proprietà di Markov. L’idea trae origine dalla fisica e in particolare…
Caratteristica (apprendimento automatico)
Nel campo dell’apprendimento automatico, una caratteristica è una proprietà individuale e misurabile di un fenomeno osservato. La scelta di caratteristiche discriminanti, ad alto contenuto informativo e indipendenti fra loro è un passo cruciale per ottenere un efficiente algoritmo di riconoscimento di pattern, classificazione e regressione. Il valore di una feature viene solitamente reso in forma numerica; esistono tuttavia delle eccezioni, come nel riconoscimento sintattico di pattern, in cui vengono considerate caratteristiche strutturali come stringhe e grafi. Il concetto di “caratteristica” è correlato a quello di variabile esplicativa usato in tecniche statistiche come la regressione lineare.
Classificatore (matematica)
In matematica e nell’apprendimento automatico, un classificatore è una mappatura da uno spazio di feature X a un insieme di etichette Y. Un classificatore può essere prefissato o basato su apprendimento automatico. Questi ultimi tipi di classificatori si dividono in supervisionati e non supervisionati, secondo se fanno uso o meno di un insieme di addestramento per apprendere il modello di classificazione.
Classificatore bayesiano
Un classificatore bayesiano è un classificatore basato sull’applicazione del teorema di Bayes.
Classificatore lineare
Nel campo dell’apprendimento automatico, l’obiettivo della classificazione statistica è utilizzare le caratteristiche di un oggetto per identificare a quale classe appartiene. Un classificatore lineare realizza ciò prendendo una decisione di classificazione basata sul valore di una combinazione lineare delle caratteristiche. Le caratteristiche di un oggetto sono anche conosciute come valori di caratteristiche e sono tipicamente presentate alla macchina in un vettore chiamato vettore di caratteristiche. Questi classificatori funzionano bene per problemi pratici come la classificazione dei documenti e, più in generale, per problemi con molte variabili (caratteristiche), raggiungendo livelli di accuratezza paragonabili ai classificatori non lineari mentre richiedono meno tempo per allenarsi ed essere usati.
Classificazione multi-etichetta
Nell’apprendimento automatico la classificazione multi-etichetta è una variante del problema della classificazione che ammette per ogni istanza l’assegnazione di più di una etichetta-obiettivo. La classificazione multi-etichetta non deve essere confusa con la classificazione multiclasse, che è invece il problema di categorizzare le istanze in una sola tra più di due classi.
Classificazione statistica
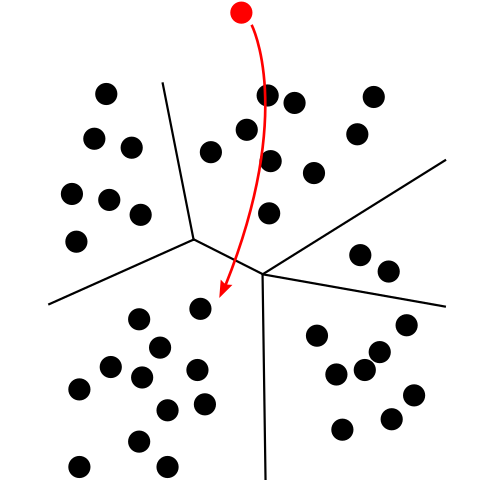
La classificazione statistica è quell’attività che si serve di un algoritmo statistico al fine di individuare una rappresentazione di alcune caratteristiche di un’entità da classificare, associandole una etichetta classificatoria. Tale attività può essere svolta mediante algoritmi di apprendimento automatico supervisionato o non supervisionato. Esempi di questi algoritmi sono:…
Clustering
In statistica, il clustering o analisi dei gruppi è un insieme di tecniche di analisi multivariata dei dati volte alla selezione e raggruppamento di elementi omogenei in un insieme di dati.
Clustering gerarchico
In statistica e apprendimento automatico, il clustering gerarchico è un approccio di clustering che mira a costruire una gerarchia di cluster. Le strategie per il clustering gerarchico sono tipicamente di due tipi:
- Agglomerativo: si tratta di un approccio “bottom up” in cui si parte dall’inserimento di ciascun elemento in un cluster differente e si procede quindi all’accorpamento
Cognitrone

Il cognitrone è una rete neurale artificiale non supervisionata multistrato di tipo gerarchico finalizzata al riconoscimento di pattern. Esso fu pubblicato dallo scienziato Kunihiko Fukushima nel 1975. I neuroni del cognitrone si distinguono in inibitori ed eccitatori, e i collegamenti sinaptici tra essi hanno la caratteristica di auto organizzarsi allo scopo di…
Compromesso bias-varianza

Nella statistica e nell’apprendimento automatico, il compromesso bias-varianza è la proprietà di un modello secondo cui la varianza del parametro stimato tra i campioni può essere ridotta aumentando il bias nei parametri stimati. Il dilemma o problema della bias-varianza sta nel conflitto nel tentativo di minimizzare contemporaneamente queste due fonti di errore che impediscono agli algoritmi…
Conditional random field
I Conditional Random Field sono una classe di metodi di modellazione statistica spesso utilizzati nel riconoscimento di pattern e nell’apprendimento automatico anche per predizioni strutturate. Mentre un generico classificatore prevede un’etichetta per un singolo campione senza considerare i campioni “vicini”, un CRF può tenere conto anche del contesto. A tale scopo, le predizioni sono basate su un modello grafico che rappresenta la presenza di dipendenze tra le variabili aleatorie. Il tipo di grafo utilizzato dipende dall’applicazione. Ad esempio, nell’elaborazione del linguaggio naturale sono diffuse le CRF “a catena lineare”, nelle quali ogni variabile dipende solo dai suoi vicini immediati. Nell’elaborazione delle immagini, il grafo in genere collega le posizioni a posizioni vicine e/o simili per garantire che ricevano predizioni simili.
Dataset Iris

Il dataset Iris è un dataset multivariato introdotto da Ronald Fisher nel 1936. Consiste in 150 istanze di Iris misurate da Edgar Anderson e classificate secondo tre specie: Iris setosa, Iris virginica e Iris versicolor. Le quattro variabili considerate sono la lunghezza e la larghezza del sepalo e del petalo. A causa di errori, esistono diverse versioni del dataset utilizzate nella letteratura scientifica.
Deepfake

Il deepfake è una tecnica per la sintesi dell’immagine umana basata sull’intelligenza artificiale, usata per combinare e sovrapporre immagini e video esistenti con video o immagini originali, tramite una tecnica di apprendimento automatico, conosciuta come rete antagonista generativa. È stata anche usata per creare falsi video pornografici ritraenti celebrità e per le porno vendette, ma può anche essere usato per creare notizie false, bufale e truffe, per compiere atti di ciberbullismo o altri crimini informatici di varia natura oppure per satira.
Dendrogramma

Il dendrogramma è un albero utilizzato per visualizzare la somiglianza nel processo di “raggruppamento”. Nelle tecniche di clustering, il dendrogramma viene utilizzato per fornire una rappresentazione grafica del processo di raggruppamento delle istanze, che esprime:…
Discesa stocastica del gradiente
La discesa stocastica del gradiente è un metodo iterativo per l’ottimizzazione di funzioni differenziabili, approssimazione stocastica del metodo di discesa del gradiente (GD) quando la funzione costo ha la forma di una somma. SGD opera similmente a GD ma, ad ogni iterazione, sostituisce il valore esatto del gradiente della funzione costo con una stima ottenuta valutando il gradiente solo su un sottinsieme degli addendi. È ampiamente usato per l’allenamento di una varietà di modelli probabilistici e modelli di apprendimento automatico, come macchine a vettori di supporto, regressione logistica e modelli grafici. In combinazione con il metodo di retropropagazione dell’errore, è lo standard de facto per l’allenamento delle reti neurali artificiali.
F1 score
Nell’analisi statistica della classificazione binaria, l’F1 score (nota anche come F-score o F-measure, letteralmente “misura F”) è una misura dell’accuratezza di un test. La misura tiene in considerazione precisione e recupero del test, dove la precisione è il numero di veri positivi diviso il numero di tutti i risultati positivi, mentre il recupero è il numero di veri positivi diviso il numero di tutti i test che…
Foresta casuale

Una foresta casuale è un classificatore d’insieme ottenuto dall’aggregazione tramite bagging di alberi di decisione L’algoritmo per la creazione di foreste casuali fu sviluppato originariamente da Leo Breiman e Adele Cutler.Le foreste casuali sono state proposte come soluzione atta a…
Funzione obiettivo
In ottimizzazione matematica e nella teoria della decisione, una funzione obiettivo o funzione di costo o ancora funzione di perdita è una funzione che mappa un evento, o valori di una o più variabili, su un numero reale intuitivamente rappresenta un “costo” associato all’evento. Un problema di ottimizzazione cerca di minimizzare una funzione di costo. Mentre la funzione di costo o di perdita indicano una funzione da minimizzare, la funzione obiettivo denota una funzione che può essere necessario massimizzare; si parla allora di funzione di rinforzo, funzione di utilità, funzione di fitness, ecc…).
GPT-3

Generative Pre-trained Transformer 3 (GPT·3) è un modello linguistico di grandi dimensioni autoregressivo che utilizza l’apprendimento profondo per produrre testo simile al linguaggio naturale umano. “Si tratta di un algoritmo di Natural Language Generation, un settore della linguistica computazionale focalizzato sulla generazione automatica di espressioni linguistiche che siano morfologicamente, sintatticamente e semanticamente corrette e il più possibile simili all’uso umano della lingua”.
Gradient boosting
Gradient boosting è una tecnica di machine learning di regressione e problemi di Classificazione statistica che producono un modello predittivo nella forma di un insieme di modelli predittivi deboli, tipicamente alberi di decisione. Costruisce un modello in maniera simile ai metodi di boosting, e li generalizza permettendo l’ottimizzazione di una funzione di perdita differenziabile arbitraria.
Griglia di ricerca
Nel contesto dell’apprendimento automatico, una griglia di ricerca è una ricerca esasustiva attraverso un sottoinsieme di uno spazio di iperparametri di un algoritmo di apprendimento per risolvere un problema dell’ottimizzazione della selezione dell’iperparametro. Un algoritmo della griglia di ricerca deve essere guidato da alcune metriche di prestazione, misurata dalla cross-validazione su un insieme di allenamento.
Macchine a vettori di supporto

Le macchine a vettori di supporto sono dei modelli di apprendimento supervisionato associati ad algoritmi di apprendimento per la regressione e la classificazione. Dato un insieme di esempi per l’addestramento, ognuno dei quali etichettato con la classe di appartenenza fra le due possibili classi, un algoritmo di addestramento per le SVM costruisce un modello che assegna i nuovi esempi a una delle due classi, ottenendo quindi un classificatore lineare binario non probabilistico. Un modello SVM è una rappresentazione degli esempi come punti nello spazio, mappati in modo tale che gli esempi appartenenti alle due diverse categorie siano chiaramente separati da uno spazio il più possibile ampio. I nuovi esempi sono quindi mappati nello stesso spazio e la predizione della categoria alla quale appartengono viene fatta sulla base del lato nel quale ricade.
Metodo kernel

In informatica, i metodi kernel sono una classe di algoritmi per l’analisi di schemi, il cui elemento maggiormente conosciuto sono le macchine a vettori di supporto (SVM).
Minima lunghezza di descrizione
Il principio della minima lunghezza di descrizione (MLD) (in inglese minimum description length [MDL] principle) è una formalizzazione del Rasoio di Occam nella quale la migliore ipotesi per un determinato insieme di dati è quella che conduce alla migliore compressione dei dati. La MLD fu introdotta da Jorma Rissanen nel 1978. È un importante concetto nella teoria dell’informazione e nella teoria dell’apprendimento.
Minimizzazione del rischio empirico
Nella teoria dell’apprendimento statistico, la minimizzazione del rischio empirico è un principio che definisce una famiglia di algoritmi di apprendimento e viene utilizzato per fornire limiti teorici alle loro prestazioni.
MLOps

MLOps o ML Ops è un insieme di pratiche che mira a sviluppare e mantenere i modelli di apprendimento automatico in produzione in modo affidabile ed efficiente. La parola è un composto di “apprendimento automatico” e DevOps, la metodologia di sviluppo del software. I modelli di apprendimento automatico sono testati e sviluppati in sistemi sperimentali isolati. Quando un algoritmo è…
MNOD

Il Multi-Networks for Object Detection è un algoritmo di computer vision per l’identificazione di oggetti di interesse in immagini generiche.
Modello di diffusione
Nell’apprendimento automatico, i modelli di diffusione, noti anche come modelli probabilistici di diffusione, sono una classe di modelli di variabili latenti. Essenzialmente sono catene di Markov allenate tramite inferenza variazionale. L’obiettivo dei modelli di diffusione è imparare la struttura latente di un insieme di dati modellando il modo in cui i dati puntuali si diffondono attraverso lo spazio latente. Nella visione artificiale, questo si traduce nell’allenare una rete neurale a eliminare il rumore da immagini offuscate utilizzando rumore gaussiano imparando a invertire il processo di diffusione.
Modello linguistico di grandi dimensioni
Un modello linguistico di grandi dimensioni, noto anche con l’inglese large language model è un tipo di modello linguistico notevole per essere in grado di ottenere la comprensione e la generazione di linguaggio di ambito generale. Gli LLM acquisiscono questa capacità adoperando enormi quantità di dati per apprendere miliardi di parametri nell’addestramento e consumando grandi risorse di calcolo nell’operatività. L’aggettivo “grande” presente nel nome si riferisce alla grande quantità di parametri del modello probabilistico. Gli LLM sono in larga parte reti neurali artificiali e in particolare trasformatori e sono (pre-)addestrati usando l’apprendimento autosupervisionato o l’apprendimento semisupervisionato.
Object recognition

Nella visione artificiale, il riconoscimento di oggetti, in inglese object recognition, è la capacità di trovare un determinato oggetto in una sequenza di immagini o video. L’essere umano riconosce una moltitudine di oggetti in immagini con poco sforzo, nonostante il fatto che l’immagine degli oggetti possa variare un…
Particle Swarm Optimization

In informatica, l’ottimizzazione con sciami di particelle, nota anche come particle swarm optimization (PSO), è un algoritmo di ottimizzazione e appartiene ad una particolare classe di algoritmi utilizzati in diversi campi, tra cui l’intelligenza artificiale. È un metodo euristico di ricerca ed ottimizzazione, ispirato al movimento degli sciami.
Phraser
Phraser è un software che utilizza algoritmi di apprendimento automatico per aiutare a creare descrizioni in linguaggio naturale per le reti neurali.
Problema della scomparsa del gradiente
Il problema della scomparsa del gradiente è un fenomeno che crea difficoltà nell’addestramento delle reti neurali profonde tramite retropropagazione dell’errore mediante discesa stocastica del gradiente. In tale metodo, ogni parametro del modello riceve a ogni iterazione un aggiornamento proporzionale alla derivata parziale della funzione di costo rispetto al parametro stesso. Una delle principali cause è la presenza di funzioni di attivazione non lineari classiche, come la tangente iperbolica o la funzione logistica, che hanno gradiente a valori nell’intervallo . Poiché nell’algoritmo di retropropagazione i gradienti ai vari livelli vengono moltiplicati tramite la regola della catena, il prodotto di numeri in decresce esponenzialmente rispetto alla profondità della rete. Quando invece il gradiente delle funzioni di attivazione può assumere valori elevati, un problema analogo che può manifestarsi è quello dell’esplosione del gradiente.


Processo gaussiano
In teoria delle probabilità un processo gaussiano è un processo stocastico f(x) tale che prendendo un qualsiasi numero finito di variabili aleatorie, dalla collezione che forma il processo aleatorio stesso, esse hanno una distribuzione di probabilità congiunta gaussiana.
Q-learning
Q-learning è uno dei più conosciuti algoritmi di apprendimento per rinforzo. Fa parte della famiglia di algoritmi adottati nelle tecniche delle differenze temporali, relative ai casi di modelli a informazione incompleta. Uno dei suoi maggiori punti di rilievo consiste nell’abilità di comparare l’utilità aspettata delle azioni disponibili senza richiedere un modello dell’ambiente.
Regolarizzazione (matematica)

In matematica e statistica, particolarmente nei campi dell’apprendimento automatico e dei problemi inversi, la regolarizzazione implica l’introduzione di ulteriore informazione allo scopo di risolvere un problema mal condizionato o per prevenire l’eccessivo adattamento. Tale informazione è solitamente nella forma di una penalità per complessità, tale come una restrizione su una funzione liscia o una limitazione sulla norma di uno spazio vettoriale.
Regressione di Poisson
In statistica, la regressione di Poisson è una forma di modello lineare generalizzato di analisi di regressione usato per modellare il conteggio dei dati in tabelle contingenti. La regressione di Poisson assume che la variabile di risposta Y ha una distribuzione di Poisson, e assume che il logaritmo del suo valore aspettato possa essere modellato da una combinazione lineare di parametri sconosciuti. La regressione di Poisson è talvolta conosciuta anche come modello log-lineare, specialmente quando viene usato per modellare tabelle contingenti.
Riconoscimento di pattern
Il riconoscimento di pattern è una sottoarea dell’apprendimento automatico. Esso consiste nell’analisi e identificazione di pattern all’interno di dati grezzi al fine di identificarne la classificazione. La maggior parte della ricerca nel campo riguarda metodi di apprendimento supervisionato e non supervisionato.
Riduzione della dimensionalità
La riduzione della dimensionalità, o riduzione della dimensione, è la trasformazione dei dati da uno spazio di dimensione più alta a uno di dimensione minore, in modo che questa rappresentazione mantenga alcune proprietà significative dei dati di origine, idealmente vicina alla sua dimensione intrinseca. Lavorare con spazi ad alta dimensionalità può essere indesiderabile per molte ragioni: i dati grezzi sono spesso sparsi come conseguenza della “maledizione della dimensionalità” e l’analisi dei dati è di solito più computazionalmente sconveniente. La riduzione della dimensionalità è comune nei campi che trattano un gran numero di osservazioni o un gran numero di variabili, come l’elaborazione del segnale, il riconoscimento vocale, la neuroinformatica e la bioinformatica.
Rilevamento delle anomalie
Nell’analisi dei dati, il rilevamento delle anomalie è l’identificazione di osservazioni, elementi, eventi rari che differiscono in modo significativo dalla maggior parte dei dati. Tipicamente gli elementi anomali porteranno a qualche tipo di problema, ad esempio casi di frode bancaria, difetti strutturali, problemi medici o errori in un testo. Le anomalie sono indicate anche come outlier, novelty, rumore, deviazioni o eccezioni.
SARSA
Lo stato–azione–ricompensa–stato–azione (SARSA) è un algoritmo di apprendimento di una funzione di policy per i processi decisionali di Markov, usato nelle aree dell’apprendimento per rinforzo e dell’apprendimento automatico. Fu proposto da Rummery e Niranjan col nome di “Modified Connectionist Q-Learning” (MCQ-L). L’acronimo alternativo e con cui oggi è più noto l’algoritmo, SARSA, fu proposto da Rich Sutton.
Selezione di modelli
La selezione di modelli o model selection consiste nel selezionare un modello fra vari candidati sulla base di un criterio di valutazione delle prestazioni utile a scegliere i migliori. Nell’ambito dell’apprendimento automatico e, più in generale, dell’analisi statistica essa riguarda la scelta di un modello statistico in un insieme di modelli candidati, basata sui dati a disposizione. Nei casi più semplici, si considera un insieme preesistente di dati. Tuttavia, tale attività potrebbe comportare anche una vera e propria progettazione degli esperimenti atta a rendere i dati raccolti adeguati al problema di scelta dei modelli. In caso di candidati dotati di capacità predittive o esplicative confrontabili, è verosimile che il modello più semplice costituisca la scelta migliore.
Sintografia

La sintografia è il metodo per generare sinteticamente immagini digitali utilizzando l’apprendimento automatico. Si distingue da altri metodi di creazione e modifica grafica per l’utilizzo di modelli di intelligenza artificiale Text-to-Image per la generazione di media sintetici. È comunemente ottenuto mediante descrizioni testuali di “prompt engineering” come input per creare o modificare…
Stima kernel di densità
In statistica, la stima kernel di densità è un metodo non parametrico utilizzato per il riconoscimento di pattern e per la classificazione attraverso una stima di densità negli spazi metrici, o spazio delle feature. Per ogni all’interno dello spazio delle feature, l’algoritmo permette di calcolare la probabilità di appartenere ad una classe considerando la densità di in un intorno del punto Il metodo si basa su un intorno di dimensione fissa calcolata in funzione del numero di osservazioni






T-distributed stochastic neighbor embedding
t-distributed stochastic neighbor embedding (t-SNE) è un algoritmo di riduzione della dimensionalità sviluppato da Geoffrey Hinton e Laurens van der Maaten, ampiamente utilizzato come strumento di apprendimento automatico in molti ambiti di ricerca. È una tecnica di riduzione della dimensionalità non lineare che si presta particolarmente all’embedding di dataset ad alta dimensionalità in uno spazio a due o tre dimensioni, nel quale possono essere visualizzati tramite un grafico di dispersione. L’algoritmo modella i punti in modo che oggetti vicini nello spazio originale risultino vicini nello spazio a dimensionalità ridotta, e oggetti lontani risultino lontani, cercando di preservare la struttura locale.
Teoria dell’apprendimento statistico
La teoria dell’apprendimento statistico è il fondamento teorico su cui si basa l’apprendimento automatico.
Training e test set
Nell’apprendimento automatico un training set è un insieme di esempi ad ognuno dei quali è associata una risposta, il valore di un attributo-obiettivo, ossia un valore categorico, cioè una classe, o un valore numerico. Tali esempi vengono utilizzati per addestrare un modello predittivo supervisionato capace di determinare il valore-obiettivo per nuovi esempi. Un modello addestrato può essere valutato su un nuovo insieme di esempi, il test set, non utilizzati in fase di addestramento.
Trasformatore (informatica)
![]()
In informatica e più precisamente nell’apprendimento automatico, un trasformatore è un modello di apprendimento profondo che adotta il meccanismo della auto-attenzione, pesando differentemente la significatività di ogni parte dei dati in ingresso. È usato primariamente nelle branche dell’elaborazione del linguaggio naturale e della visione artificiale.
Version space

Un version space, nel campo del concept learning, è il sottoinsieme di tutte le ipotesi consistenti con gli esempi di training osservati.
Word2vec
Word2vec è un insieme di modelli che sono utilizzati per produrre word embedding, il cui pacchetto fu originariamente creato in C da Tomas Mikolov, poi implementato anche in Python e Java. Word2vec è una semplice rete neurale artificiale a due strati progettata per elaborare il linguaggio naturale, l’algoritmo richiede in ingresso un corpus e restituisce un insieme di vettori che rappresentano la distribuzione semantica delle parole nel testo. Per ogni parola contenuta nel corpus, in modo univoco, viene costruito un vettore in modo da rappresentarla come un punto nello spazio multidimensionale creato. In questo spazio le parole saranno più vicine se riconosciute come semanticamente più simili. Per capire come Word2vec possa produrre word embedding è necessario comprendere le architetture CBOW e Skip-Gram.




